|
|
The Drug EngineAlexander
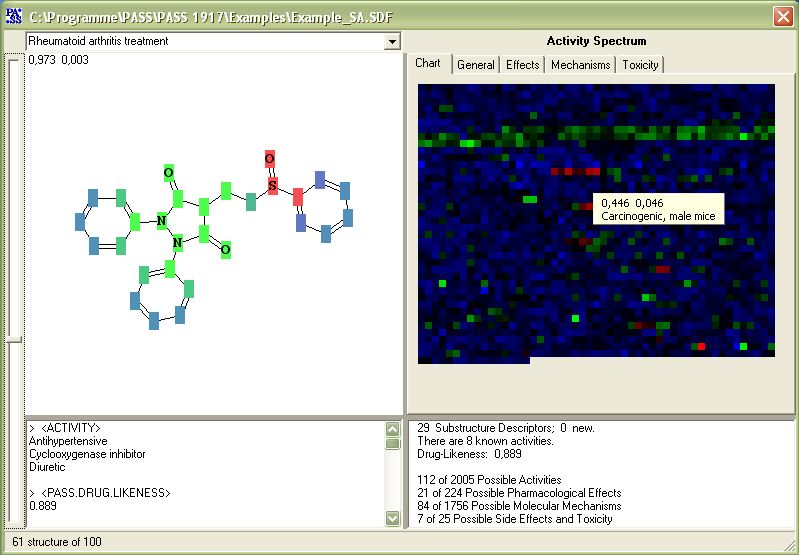
Kos updated August 10, 2005AbstractMany parts of the drug discovery process are automated and supported with software and databases. Modelling, chemoinformatics, bioinformatics, and biological systems have interfaces that, at least in theory, make it possible to generate an integrated system. DiscoveryGate is a development with the goal to integrate all databases thus helping the scientist to find all available sources. Underneath an index layer are the systems that hold and manage the data. This can be a commercial database like ACD or reaction databases. Further down is the original literature, the journal, or the notebook. Isentris is the technology that brings together the applications and data in one application. IntroductionJuly 17, 1977, 11:00 Todd Wipke then professor at Princeton, and Stuart Marson decided to found a business helping companies to design molecules on the computer. This could be considered the birth date for Molecular Design Limited, Inc. (MDL) as the company was finally called that started business in 1978. When Stuart Marson went to Chevron Agro Chemical division and told them he would help make new active drugs on the computer he probably met some scepticism, but he got them interested. When visiting MDL they saw Todd Wipke's database system MOLEX, and decided to start with this. Since the name MOLEX was already taken by another company, Todd Wipke used a program to invent names and the first product of MDL was called MACCS (Molecular ACCess System.). And the designing of molecules was left to others. Stuart never gave up his dream and when he was selling to Kodak the first structure-oriented reaction based system; he made a huge slide show, which MDL used for several years. One slide showed the “drug machine”. It looked like an antiquated harvester, on the top you put in the idea, on the bottom you got the recipe for the new wonder drug. Well – who wouldn’t want such a machine and isn’t this driving all the computer development in chemical research? Let’s crawl inside this machine and have a look at the gears and tubes and see what is in place, what needs to be connected, and what is missing. Since the first version of this text in 1998 a lot happened, but the machine is far from perfect, and we certainly can continue to hammer and weld this machine to the end of our time. NoveltyBefore we go on with our idea to find a new drug we have to investigate if it is novel and/or if it is already claimed. The first look is probably in CAS (Chemical Abstract Services) or DiscoveryGate. Most chemists have access to a person who searches in CAS or has his own on-line access. DiscoveryGate includes in a search the MDL Screening Compounds Directory (SCD), and SciFinder contains CHEMCATS. Both are databases of screening compound collections that were never published, and a thorough search should include these sources. DiscoveryGate also covers the patent literature with Derwents World Patent Index, and the MDL Chemistry Patent Database. On the Internet are also some sources, but, presently they are more obscure and there is no way to make a comprehensive search. For larger companies it is essential to search the own records, and most companies have their own chemical information system. Many solved this with MDL technology. Some large amounts of Russian literature might be hidden in some long forgotten databases at VINITI. But even here, InfoChem’s reaction databases might offer an electronic entry. At least in large companies every researcher has access to all these databases, and a search for novelty can be performed by a bench chemists. It helps to have sophisticated user interfaces to make this task easy like SciFinder and DiscoveryGate 2.0. Isentris allows you to extend the online search to the in-house databases, and with two or three queries the accessible chemical literature can be searched. ValidationOur ideas are seldom completely new. Often a lot is known about a similar subject, but, finding something similar is a real problem. The chemists with their chemical structures are lucky. It is still difficult to find similarities, but at least you can define structure similarity. It is more difficult to find similar biological activity. Methanol and Ethanol are structural pretty similar, but try to drink it and you can tell the difference. If you needed to know 2 systems to make a structure search for novelty, you need not more systems but familiarity with the historically grown discrepancies of databases to find your answers. Structures are only in the field *structure or *reaction in a database. A term like "hepatotoxicity" might in the field "activity" in one database, in the other in the field "action", in the third you have to combine numerical data with data from a field called "organs" and "dose". ADMET data can be in Metabolite, Toxicity, CMC (Comprehensive Medicinal Chemistry), NCI, xPharm, CrossFire Beilstein, MDL Chemistry Patent Database to name only these sources that are available in DiscoveryGate. You can add many more databases and systems like from Prous publishers, or Medline etc. Symyx (MDL) have found a way to overcome this problem, at least using sources that belong to the Symyx (MDL) world. Automatic procedures are developed that mine the databases and compile the data in a more digestible form. The end user might have large difficulties adding to this their own in-house data. Actually the end user can do nothing and has to ask his IT people to help. This is not always a satisfactory answer, and Isentris gives the computer knowledgeable user back the control over his data. NMR data are in systems of the spectroscopist, pharmacological data are mainly in primary literature sources. Each data has its own special source, and that’s why information specialists have a job. However, they don’t have a good idea of what you are really looking for. They either have no answer for you or bury you in paper. And, you don’t know if they have searched all available resources. What you need is an abstraction layer that tells you which data are available. SCOPUS is on the way to provide this, but since it covers only the abstracts of publications getting detailed answers still need a lot of work. Once you have the data sources you need to correlate the data to transform them into knowledge. Knowledge you create by correlation, i.e. sort a list of compounds by activity and you know which is the most active. Typical for this sort of work is a spreadsheet, like ISIS for EXCEL that correlates the R-groups of a structure class with measured values of activities or properties. SciTegic's Pipeline Pilot is another tool that helps you in building correlations and streamlines the manipulation of data. If you use heavily programming, you might end with systems that find the hidden correlation among data und you end up with in silico methods. AvailabilityOnce you have selected your compound, you need to get hold of it. Do I have it in-house, can I buy it, can I make it? Internal inventory systems are common. Many suppliers provide access to their external inventories. ACD (Available Chemicals Directory) and SCD are the electronic catalogues for buying compounds. Reaction databases help you to find the best way to synthesize a compound. Tools for combinatorial chemistry help you to make complete libraries. ScreeningOnce you have the desired compounds available, you need to see if they fulfil your hypothesis of being useful. Today, high throughput screening allows you to start working without a hypothesis. You throw every available compound on every available assay. Very quickly everybody realizes that some pre-selection is required. In Silico ScreeningThis idea of using the computer to find (screen) the best compound was the idea of Todd Wipke and Stuart Marson, back in 1977. Then these ideas seemed unrealistic. Today armed with an array of modeling programs we can make clever predictions about small number of compounds. As it turns out a modeling study is often much slower and more expensive than running a test on the compound. QSAR techniques with neural networks try to handle larger data sets. There are not enough knowledgeable people available and these potential powerful methods are underused. Automated QSAR systems like PASS are basically one click approaches that let you quickly predict effects of your compound(s). Over 2000 possible activities are explored in a fraction of a second and the graphical colour plot lets you quickly decide if your compound might be valuable, seeing a lot of green, or there are problems, seeing a lot of red dots.
|
|
|
High Throughput ScreeningThe ease of which compounds can be tested competes with the know-how required to use and apply in silico methods. But buying compounds keeps quite a few people busy and systems that automatically remove all compounds with nitro groups or heavy metals and select only compounds under $ 50, and send the request to SAP make life easier. Reagent Selector do a great job helping in this process. Now, we can go on to our HTS laboratory. Laboratory is not the right word any more, we start going into factories where every step, from storing the samples to washing the plates is highly automated and correlated. Computer programs drive everything. Software like Assay Explorer helps you define the experiment, make the plate layout, collect the results from the reader, and calculated the hits. OptimizationMany interesting lead compounds end up in the mountain of data that we produced in high throughput screening. Now, we need decision tools that enable us to select the best candidates. Visualization techniques provided in programs like Miner3D, Spotfire, or Partek enable you visually to choose the "best" compounds. Armed with the same tools as before, you make another circle and another, until you have distilled a few good compounds, which you promote to single screening methods. OutlookOur “drug machine” has and needs many more parts. Since the fist version of this text, ca. 7 years ago, tremendous progress has been made in getting access to the published literature. However, my observation (and purely my interpretation) is that in average the knowledge of chemists using chemoinformatics tools has not increased in the same rate as new tools became available. Many levers on this machine still need human intervention, but more and more many tedious or repetitious tasks are automated. Scientist operate the machine on ever fewer critical spots to make sure that the data, information and knowledge flow can pass on unhindered, to produce the final result – the drug.
|
|
|